
ChatGPT appears to be testing allowlists and blocklists for news websites, according to the tech news site, TestingCatalog.
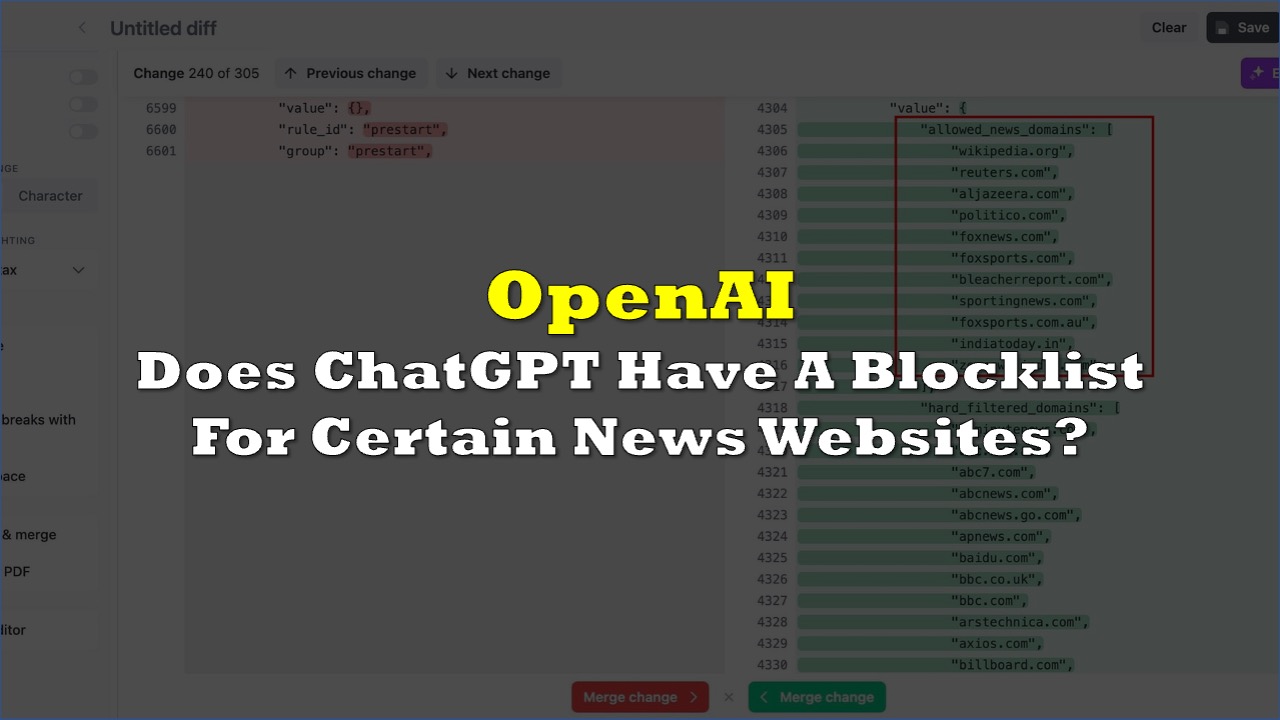
The data, according to the publication which used reverse-engineering efforts to obtain the data, was seen as a list of different domains in five categories in the latest web release of OpenAI’s large language model ChatGPT.
Testing on ChatGPT 4, they found that asking for recent information (e.g. “What is the latest news on [news site]?”) works for the domains listed in the allowlist and does not for those on the blocklist.

“It is not fully clear if this list is experimental or if it is overriding another internal instruction but it makes one point visible — not all domains will be treated equally by OpenAI,” they wrote.
According to ChatGPT, the company’s “approach to curating sources and information within ChatGPT involves a careful selection process aimed at providing accurate, reliable, and non-misleading information to users.” They claim that these decisions are influenced by a number of factors including reliability and accuracy, bias and objectivity, content policies (meaning they block sites that “promote hate speech, misinformation, or other harmful content”), and quality control.
Curiously, the allowlist appears to be very short: wikipedia.org, reuters.com, aljazeera.com, politico.com, foxnews.com, foxsports.com, bleacherreport.com, sportingnews.com, foxsports.com.au, indiatoday.in, zeenews.india.com. It also includes Fox News, which paid Dominion Voting Systems $787.7 million to settle a defamation case that alleged the network spread election disinformation.
The blocklist, on the other hand, is a long one and it includes the other mainstream media sites as well as smaller outfits like Axios, Ars Technica, Business Insider, Tech Radar, Rolling Stone, and Vox. You can see the full lists in the TestingCatalog article here.
The blocklist may also be a response to major media outlets blocking ChatGPT from crawling and training on their content. In August, it was reported that a growing number of sites have started to block OpenAI’s web crawler, GPTBot.
Information for this story was found via the sources and companies mentioned. The author has no securities or affiliations related to the organizations discussed. Not a recommendation to buy or sell. Always do additional research and consult a professional before purchasing a security. The author holds no licenses.







