

“UI”, and “UX” weren’t considerations in the pre-iMac world where the crude instrument that was Original SEDAR was forged. System for Electronic Document Analysis and Retrieval is the kind of name they gave computer systems in an era where computers were all business, and the notion that it would ever have to appeal to consumers hadn’t occurred to anyone.
And that was fine. Securities research doesn’t have to be entertaining. As long as all the companies and all their filings were available… nobody was ever in a position to complain.

Primitive, unpolished and deadly, the SEDAR interface suffered little growth over the decades while the volume of information it was built to archive and retrieve has grown exponentially. As Canada’s capital market became larger and more sophisticated, there came to be more filers, and more types of filers, filing more documents, and SEDAR was able to scale up as it went, because the filing fees charged by Canada’s provincial securities regulators are effectively what finances SEDAR.
Those regulators (The BC Securities Commission, the Ontario Securities Commission, etc.) own and operate SEDAR through an umbrella organization called the Canadian Securities Administrators. The CSA doesn’t publish an annual report, because it isn’t federated or incorporated anywhere; it’s an affiliation of the provincial commissions, who all have their own rules, and aren’t interested in harmonizing them. They are interested in having a sole digital depository for regulatory filings, though, so they all require the companies they govern to make filings on SEDAR, which they own and administrate for the benefit of free and open information, and free and open markets.
Just to get an idea of SEDAR’s financial shape and weight, we’ve worked backwards from the 2021/2022 annual report of the BCSC, which owns 25% of SEDAR, to infer that SEDAR drew $28.4 million in user fees in the year ending August 2022, against $23.6 million in expenses. BCSC’s take from SEDAR revenue represented only 8% of its total 2022 revenue. The bulk of its revenue comes from the fees it charges for distributions and registration. Enforcement and sanction payments make up only 5%.
“I’m very interested but… can you just give me the gist of it?”
The weird and clunky original SEDAR system played an important part in The Deep Dive‘s origin story. As the banking exercise that was Canadian cannabis legislation developed and rolled out in 2017 – 2019, millions of retail investors couldn’t stand the thought of everyone but them getting rich. Venture stage cannabis companies were coming out of the woodwork, offering average people the chance to be the proud shareholder of companies with a chance to grow to be as large and profitable as liquor and tobacco companies in short order. An army of professional middlemen were building smallcap cannabis co’s up, promoting them on any channel that got traffic, all the while cautioning their marks to “do their due diligence.”
Retail investors weren’t interested in figuring out what all those filings were, what they meant, or how to get after them. They just wanted to get RICH. That presented a journalistic opportunity for Deep Dive staff, who had the patience to put up with old SEDAR, and the experience to know what to look up and publish to bring context to any given cannabis company’s latest assertions.
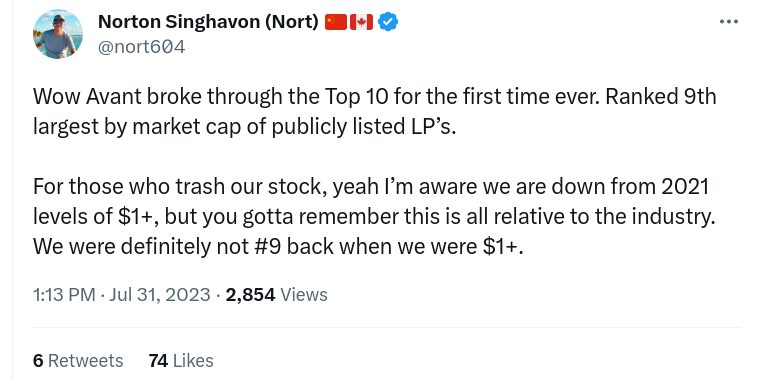
This guy, for example, likes to wax poetic on twitter about how far Avant Brands (TSX:AVNT) (formerly GTEC) has come. He isn’t telling any lies here, but he’s pretty proud of himself… Who wants to go run the SEDAR maze to find out if he’s being a straight shooter?
The DIVE, that’s who! We’ve been clipping the parts of SEDAR filings that we can make funny jokes out of since 2017 or so, and the retail investing crowd appreciates it, and we appreciate them.
We’re drawing this out to say that SEDAR is near and dear to us. We used it to put ourselves on the map during the cannabis boom, and we still use it to stay on top of relevant companies and practice informed journalism about Canadian markets. It’s sentimental, sure, but SEDAR means enough to us that we want it to be good and useful.
Worse is putting it mildly
From a reader’s-side perspective, SEDAR Classic was convoluted, but functional. It was a big long list of Canadian public filers, each one linking to a list of the filings they’d made over the years, in the order they made them.
The old site also allowed for the viewing of filings by date, and the most recent filings for all the companies and funds as they came in. The ability to view the filings by currency was handy for journalists and swing traders, but it’s gone now, an apparent victim of the move to SEDAR+.

The modernization of SEDAR was proposed in 2019. It involved the updating of various National Securities Instruments, an update of the filing and payments system used by the public filers and their professional service providers, and a re-arranging of the deck-chairs on the front-end interface.
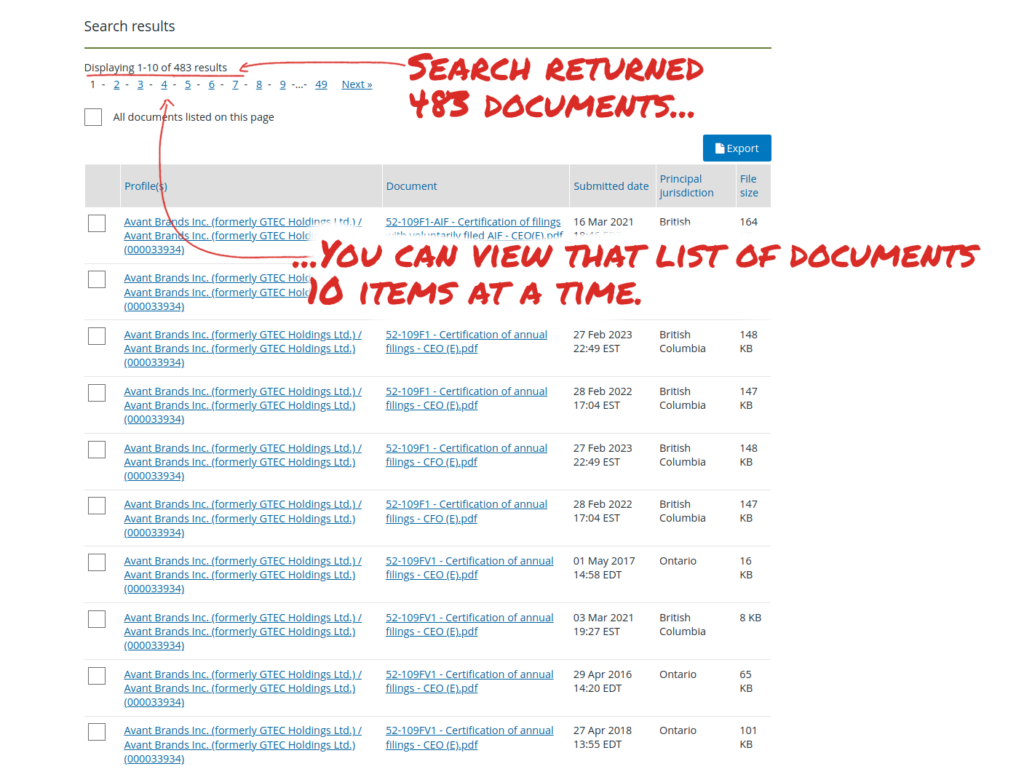
Complaints from Deep Dive editors and contributors include ongoing service outages, the aforementioned elimination of easy chronological viewing of files, the downloading of every file viewed, and an inexplicable limiting of the document search results to ten items per page.
This author is of the opinion that it sucks at least as much as SEDAR Classic, and everyone who expected anything different is a starry eyed dreamer; if the system’s architects wanted this to be a useful instrument, they’d have made it into one a long time ago.
Doomed to embarrass everyone involved
One of the responses filed during the six month public comment period of Proposed National Systems Renewal Program was filed by the CFA Societies of Canada, who seemed excited by the prospect of an improved SEDAR, and noted that if the administrators paid attention to how SEDAR was being searched, and what for, it could learn a lot about the investing public and the country’s business landscape, and about the database it maintains, and improve itself. They mentioned that the SEC had done this type of data mining with the United States’ SEDAR counterpart, EDGAR, and that it had paid off.
It’s good thinking, and it’s the sort of thing that might be considered helpful if it wasn’t being submitted to such a weird, byzantine organization, determined to go nowhere.
EDGAR is run by the SEC, a US Federal authority that isn’t an umbrella organization for anything. It oversees a set of regulations designed to maintain orderly markets and facilitate the free and open flow of information from companies to the general public. EDGAR is fully and totally digitized. Every filing and the data that it contains is available to the public, not only through a front-end web portal, but also through a series of free APIs.
EDGAR filers are required to provide their financial statements in digital, machine readable XBRL, which can then be translated into XML, JSON, or whatever kind of data-friendly format one might want it in. It’s all available for granular queries to anyone who wants it. If someone wanted, say, the gross revenue of all public American oil companies from 2003-2007 inclusive, they could write a few lines of code that queried data.sec.gov, and the API would spit it out in a few seconds.
There are free python libraries that can pull EDGAR filings by section, and in batches. The data gets used by academics, business people, government, policy makers… all the time and without having to ask anyone for it, or hire anyone to compile it.
The SEC devotes time and attention to making it available, because that’s what’s best for everyone. It’s public information with public value and, until it’s fully available and accessible, there’s no way to tell just how valuable it is. Many successful web businesses have been built on querying US investor data (for free), and presenting it in a format that readers want to see. Mike Bloomberg built an empire on it.
But Canadian public filers aren’t required to submit machine readable formats of financial statements or anything else. The “voluntary” XBRL filing program that was available to SEDAR filers remains available under SEDAR+ – a literal sideways move to nowhere.
We don’t know why the CSA built the old SEDAR and the new SEDAR+ in a way that discourages and prevents data mining. It could be that it just doesn’t understand what it’s doing, and it could be that it can’t stand the thought of someone making money off of the public’s data, and not kicking up a cut. It hardly matters why: the result is an embarrassing mess.
All the world’s access to the filings of Canadian public companies is all being funnelled through the same user interface, accessed by the same search algorithm. The results of those searches are all PDF documents, to be parsed directly by the eyes and minds of human users. Nobody has an opportunity to parse it any differently, or build anything that allows for the data to be learned from in any kind of modern, algorithmic way. The archive of PDFs that the CSA has created (and re-created) gets us out of manual filing chores, but that’s all it does.
Canada’s securities regulators make Canada’s public markets look like a Banana Republic full of toll roads, which is appropriate, because that’s what it is. Various fiefdoms claim territorial control of the ability to charge a fee for issuing securities, and occasionally make a show of prosecuting the individuals behind the companies who use them to rip off the investing public, when it’s necessary.
After all: the documents are all available on SEDAR, so there’s no excuse for investors who don’t do their due diligence.
Information for this briefing was found via SEDAR, EDGAR, and the sources mentioned. The author has no securities or affiliations related to the organizations discussed. Not a recommendation to buy or sell. Always do additional research and consult a professional before purchasing a security. The author holds no licenses.








One Response
Agreed. The old system was clunky, and looked like it was based on on DOS 3.0, but it worked well and quickly.
since it’s difficult to tell what is in a particular filing, who the heck wants to download the document before seeing what it is? What brain trust came up w/ that approach? I have to think the people who (re)designed the site don’t actually use it…